
Solid in practice - Open Closed Principle
This is the second episode of the series. The screencast contains explanation of open closed principle.
It also gives an practical example of a class violating this principle and how to fix it.
This is the second episode of the series. The screencast contains explanation of open closed principle.
It also gives an practical example of a class violating this principle and how to fix it.
The screencast contains explanation of single responsible principle.
It also gives an practical example of a class violating this principle and how to fix it.
The project can be cloned from github repository.
The revision described in this post is 5afeaa64a7fb22fad7fe2c30ee440d9a3ff25337.
In the previous 19 posts I’ve been describing the process of creating my very first programming language. All that hard work I’ve put into it would seem pointless if I’d never used it for anything useful, right?
I came up with an idea of playing cards drawing simulator. The idea is to provide number of players and number of cards per player. As an output you get randomized collection of cards for each player. Just like in real games the cards are being removed from the stack when drawing.
Card {
string color
string pattern
Card(string cardColor,string cardPattern) {
color = cardColor
pattern = cardPattern
}
string getColor() {
color
}
string getPattern() {
pattern
}
string toString() {
return "{" + color + "," + pattern + "}"
}
}
There is nothing fancy here. Just simple domain object. It is immutable representation of a playing card.
CardDrawer {
start {
var cards = new List() //creates java.util.ArrayList
addNumberedCards(cards) //calling method with 3 arguments (last 2 are default)
addCardWithAllColors("Ace",cards)
addCardWithAllColors("Queen",cards)
addCardWithAllColors("King",cards)
addCardWithAllColors("Jack",cards)
//Calling with named arguments (and in differnet order)
//The last parameter (cardsPerPlayer) is ommited (it's default value is 5)
drawCardsForPlayers(playersAmount -> 5,cardsList -> cards)
}
addNumberedCards(List cardsList,int first=2, int last=10) {
for i from first to last { //loop from first to last (inclusive)
var numberString = new java.lang.Integer(i).toString()
addCardWithAllColors(numberString,cardsList)
}
}
addCardWithAllColors(string pattern,List cardsList) {
cardsList.add(new Card("Clubs",pattern))
cardsList.add(new Card("Diamonds",pattern))
cardsList.add(new Card("Hearts",pattern))
cardsList.add(new Card("Spades",pattern))
}
drawCardsForPlayers(List cardsList,int playersAmount = 3,int cardsPerPlayer = 5) {
if(cardsList.size() < (playersAmount * cardsPerPlayer)) {
print "ERROR - Not enough cards" //No exceptions yet :)
return
}
var random = new java.util.Random()
for i from 1 to playersAmount {
var playernumberString = new java.lang.Integer(i).toString()
print "player " + playernumberString + " is drawing:"
for j from 1 to cardsPerPlayer {
var dawnCardIndex = random.nextInt(cardsList.size() - 1)
var drawedCard = cardsList.remove(dawnCardIndex)
print " drawed:" + drawedCard
}
}
}
}
First we need to compile Card class (no multiple files compilation implemented yet). Once the Card is compiled CardDrawer is able to find it on classpath (providing we added current dir to classpath)
java -classpath compiler/target/compiler-1.0-SNAPSHOT-jar-with-dependencies.jar: com.kubadziworski.compiler.Compiler EnkelExamples/RealApp/Card.enk
java -classpath compiler/target/compiler-1.0-SNAPSHOT-jar-with-dependencies.jar:. com.kubadziworski.compiler.Compiler EnkelExamples/RealApp/CardDrawer.enk
kuba@kuba-laptop:~/repos/Enkel-JVM-language$ java CardDrawer
player 1 is drawing:
drawed:{Diamonds,Queen}
drawed:{Spades,7}
drawed:{Hearts,Jack}
drawed:{Spades,4}
drawed:{Hearts,2}
player 2 is drawing:
drawed:{Diamonds,4}
drawed:{Hearts,Ace}
drawed:{Diamonds,Jack}
drawed:{Spades,Queen}
drawed:{Spades,King}
player 3 is drawing:
drawed:{Diamonds,Ace}
drawed:{Clubs,2}
drawed:{Clubs,3}
drawed:{Spades,8}
drawed:{Clubs,7}
player 4 is drawing:
drawed:{Spades,Ace}
drawed:{Diamonds,3}
drawed:{Clubs,4}
drawed:{Clubs,6}
drawed:{Diamonds,2}
player 5 is drawing:
drawed:{Hearts,4}
drawed:{Hearts,Queen}
drawed:{Hearts,10}
drawed:{Clubs,Jack}
drawed:{Diamonds,8}
Great! This proofs that Enkel,though in early stage, can already be used for creating some real applications.
I had a really great time creating Enkel and sharing the whole process here. Writing code is one thing, but describing it in a way, that other people could understand it is another challenge itself.
I learned a lot during the process, and hope some other people benefited (or will benefit) from the series too.
Unfortunately this is the last post of the series. The project will however be continued, so keep track of it!
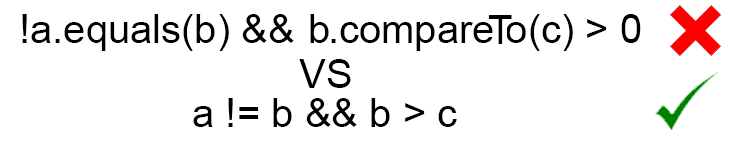
The project can be cloned from github repository.
The revision described in this post is 7e6a08eaf4272cb07138fb1ef9d5c2bb7d300df8.
Comparing objects is one of the most surprising part of the language for Java’s newcomers. Diving into the code directly without any theoretical background, one might find himself very confused by the results.
Moreover there are some traps that make the whole concept feel not deterministic. Let’s take a look at this example:
Integer a = 15;
Integer b = 15;
boolean areEqual = a == b;
There is an implicit boxing using Integer.valueOf(15) which returns cached
Integer object. Because the reference is the same areEqual is true
After executing the code above, beginner Java programmer might think to himself
==”The next day he decides to change the values:
Integer a = 155;
Integer b = 155;
boolean areEqual = a == b;
and all of the sudden areEqual is false because 155 is above caching threshold.
Strings are also traps. If you create one by explicitly calling new you get a new reference. On the other hand if you assign variable to the string value ( “ “ notation) you get a pooled object.
The problem with this is that most of the times (I’d say 99%) we
are interested in comparing relation between objects, not the
reference value. I really wish == meant relational equality,
and < , > , <= , >= called compareTo.
Instead of wishing let’s just implement it then!
In Creating JVM language [PART 10] - Conditional statements I introduced a way to compare primitive objects. The post describes how the compare operators are created. The only thing that needs to be changed is bytecode generation step.
Basically we need check if the value is primitive or reference. If the object is reference then the equals or compareTo method calls are generated:
public class ConditionalExpressionGenerator {
//Constructor and fields
public void generate(ConditionalExpression conditionalExpression) {
Expression leftExpression = conditionalExpression.getLeftExpression();
Expression rightExpression = conditionalExpression.getRightExpression();
CompareSign compareSign = conditionalExpression.getCompareSign();
if (conditionalExpression.isPrimitiveComparison()) {
generatePrimitivesComparison(leftExpression, rightExpression, compareSign);
} else {
generateObjectsComparison(leftExpression, rightExpression, compareSign);
}
Label endLabel = new Label();
Label trueLabel = new Label();
methodVisitor.visitJumpInsn(compareSign.getOpcode(), trueLabel);
methodVisitor.visitInsn(Opcodes.ICONST_0);
methodVisitor.visitJumpInsn(Opcodes.GOTO, endLabel);
methodVisitor.visitLabel(trueLabel);
methodVisitor.visitInsn(Opcodes.ICONST_1);
methodVisitor.visitLabel(endLabel);
}
private void generateObjectsComparison(Expression leftExpression, Expression rightExpression, CompareSign compareSign) {
Parameter parameter = new Parameter("o", new ClassType("java.lang.Object"), Optional.empty()); // #1
List<Parameter> parameters = Collections.singletonList(parameter);
Argument argument = new Argument(rightExpression, Optional.empty());
List<Argument> arguments = Collections.singletonList(argument);
switch (compareSign) { // #2
case EQUAL:
case NOT_EQUAL:
FunctionSignature equalsSignature = new FunctionSignature("equals", parameters, BultInType.BOOLEAN); // #3
FunctionCall equalsCall = new FunctionCall(equalsSignature, arguments, leftExpression);
equalsCall.accept(expressionGenerator); // #4
methodVisitor.visitInsn(Opcodes.ICONST_1);
methodVisitor.visitInsn(Opcodes.IXOR); // #5
break;
case LESS:
case GREATER:
case LESS_OR_EQUAL:
case GRATER_OR_EQAL:
FunctionSignature compareToSignature = new FunctionSignature("compareTo", parameters, BultInType.INT); // #6
FunctionCall compareToCall = new FunctionCall(compareToSignature, arguments, leftExpression);
compareToCall.accept(expressionGenerator);
break;
}
}
private void generatePrimitivesComparison(Expression leftExpression, Expression rightExpression, CompareSign compareSign) {
leftExpression.accept(expressionGenerator);
rightExpression.accept(expressionGenerator);
methodVisitor.visitInsn(Opcodes.ISUB);
}
}
There are few sections worth explanation:
#1
Equals method is declared in Object class as follows:
public boolean equals(Object obj) {
return (this == obj);
}
Therefore the parameter needs to be an java.lang.Object.
The name is irrelavant (o seems fine).
There is no default value (Optional.empty)
#2
It’s mandatory to distinguish whether the equality (== or !=),
or comparing (> < >= or <=) operators were used .
We could use compareTo for equality operator too but not all Classes
implement Comparable interface.
#3
As pointed out before equals method is named “equals” has one parameter
of type java.lang.Object and returns primitive boolean value.
#4
Generate bytecode responsible for calling equals method. Take a look in
CallExpressionGenerator class for more details on that.
#5
The equals returns true (1) if the objects
are equal or false (0) if the objects are different.
The primitives equality is calculated the other way around. The
values are subtracted from each other. If the result is 0 it means
values are equal, otherwise they are not.
To make things compatible, false needs to be swapped with true.
To do that I used XOR (Exclusive or) logical instruction.
The compareTo method on the other hand is very similar to primitive
comparison. It return 0 if equal too, so there is no need to make any changes.
#6
Creating call which represents compareTo call. compareTo
was introduced before generics so it also takes java.lang.Object as a parameter,
but returns int.
The following Enkel class:
EqualitySyntax {
start {
var a = new java.lang.Integer(455)
var b = new java.lang.Integer(455)
print a == b
print a > b
}
}
decompiled into Java looks like this:
public class EqualitySyntax {
public void start() {
Integer var1 = new Integer(455);
Integer var2 = new Integer(455);
System.out.println(var1.equals(var2));
System.out.println(var1.compareTo(var2) > 0);
}
public static void main(String[] var0) {
(new EqualitySyntax()).start();
}
}
As you can see == was sucesfully mapped to equals and > was mapped into compareTo.
If you are not familiar with spock it is testing framework for Groovy and Java. It’s been stable for quite some time and I highly recommend you to check it out if you are annoyed by Junit and Java’s style of writing tests.
The standard way of testing Java application is to use Junit and some mocking framework (Mockito,EasyMock, PowerMock etc.).
Java combined with those frameworks makes it rather hard to write and read tests in medium and large sizes projects:
If tests are hard to write we usually think of them as something painful and start to neglect them. Avoiding or delaying writing tests leads to the situation where application cannot be trusted anymore. We then become afraid of making any changes because other part of the app might break in some bizarre way.
It shouldn’t be this way. Test should be easy and fun to write. After all they are like a cherry on top, proving that the features are implemented correctly.
In my opinion the most important responsibility of the test is to be as most readable as possible. Business changes to the project are introduced all the time. If we change something in the application we have to change test too (unless you’re applying open-closed principle, which I’ve never heard of anyone successfully adapting :D). If tests are hard to read there is a big problem.
On the other hand - these are just my opinion, who am I to judge? Do you feel similar about this topic or is it just me? If you disagree, or have some objections leave a comment!
Spock is both testing and mocking framework. What’s more it extends Junit runner so it can be runned by the tools you used for your tests before.
The best thing about Spock is that it’s basically a DSL (domain specifing language) for writing tests. It’s based on Groovy and is designed particularly testing. It introduces some syntax features just for that purpose. You may therefore expect some neat stuff in it (which is indeed correct).
Groovy is kinda like a scripting version of Java - simple, less verbose but retains all the power of JVM.
Benefits from using spock over Junit + mocking framework:
This cheatsheet contains the most useful spock features regarding testing Java applications. Most of this is copy-paste from official spock documentation. I compiled it while I was learning the framework to have all information in one place. I figure out since it’s already compiled why not share it on a blog too.
class MyFirstSpecification extends Specification {
// fields
// fixture methods
// feature methods
// helper methods
}
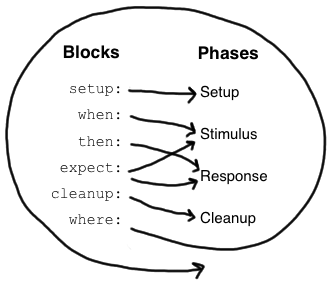
def setup() {} // run before every feature method
def cleanup() {} // run after every feature method
def setupSpec() {} // run before the first feature method
def cleanupSpec() {} // run after the last feature method
given: //data initialization goes here (includes creating mocks)
when: //invoke your test subject here and assign it to a variable
then: //assert data here
cleanup: //optional
where: //optional:provide parametrized data (tables or pipes)
or
given:
expect: //combines when with then
cleanup:
where:
| Spock | JUnit |
|---|---|
| Specification | Test class |
| setup() | @Before |
| cleanup() | @After |
| setupSpec() | @BeforeClass |
| cleanupSpec() | @AfterClass |
| Feature | Test |
| Feature method | Test method |
| Data-driven feature | Theory |
| Condition | Assertion |
| Exception condition | @Test(expected=…) |
| Interaction | Mock expectation (e.g. in Mockito) |
class Math extends Specification {
def "maximum of two numbers"(int a, int b, int c) {
expect:
Math.max(a, b) == c
where:
a | b | c
1 | 3 | 3 //passes
7 | 4 | 4 //fails
0 | 0 | 0 //passes
}
}
Input data can also be seperated with expected parameters using ||:
where:
a | b || c
3 | 5 || 5
7 | 0 || 7
0 | 0 || 0
A method annotated with @Unroll will have its rows from data table reported independently:
@Unroll
def "maximum of two numbers"() { ... }
maximum of two numbers[0] PASSED
maximum of two numbers[1] FAILED
Math.max(a, b) == c
| | | | |
| 7 0 | 7
42 false
We have to figure out which row failed manually
maximum of two numbers FAILED
Condition not satisfied:
Math.max(a, b) == c
| | | | |
| 7 0 | 7
42 false
Right side must be Collection, String or Iterable.
where:
a << [3, 7, 0]
b << [5, 0, 0]
c << [5, 7, 0]
where:
[a, b, c] << sql.rows("select a, b, c from maxdata")
where:
row << sql.rows("select * from maxdata")
// pick apart columns
a = row.a
b = row.b
c = row.c
where:
[a,b] << [[1,2,3],[1,2,3],[4,5,6]]
[a, b, _, c] << sql.rows("select * from maxdata")
where:
a | _
3 | _
7 | _
0 | _
b << [5, 0, 0]
c = a > b ? a : b
def "#person is #person.age years old"() { ... } // property access
def "#person.name.toUpperCase()"() { ... } // zero-arg method call
Mocks are Lenient (return default value for undefined mock calls)
Subscriber subscriber = Mock()
def subscriber2 = Mock(Subscriber)
def "should send messages to all subscribers"() {
when:
publisher.send("hello")
then:
1 * subscriber.receive("hello") //subsriber should call receive with "hello" once.
1 * subscriber2.receive("hello")
}
1 * subscriber.receive("hello") // exactly one call
0 * subscriber.receive("hello") // zero calls
(1..3) * subscriber.receive("hello") // between one and three calls (inclusive)
(1.._) * subscriber.receive("hello") // at least one call
(_..3) * subscriber.receive("hello") // at most three calls
_ * subscriber.receive("hello") // any number of calls, including zero
// (rarely needed; see 'Strict Mocking')
1 * subscriber.receive("hello") // a call to 'subscriber'
1 * _.receive("hello") // a call to any mock object
1 * subscriber.receive("hello") // a method named 'receive'
1 * subscriber./r.*e/("hello") // a method whose name matches the given regular expression
// (here: method name starts with 'r' and ends in 'e')
1 * subscriber.receive("hello") // an argument that is equal to the String "hello"
1 * subscriber.receive(!"hello") // an argument that is unequal to the String "hello"
1 * subscriber.receive() // the empty argument list (would never match in our example)
1 * subscriber.receive(_) // any single argument (including null)
1 * subscriber.receive(*_) // any argument list (including the empty argument list)
1 * subscriber.receive(!null) // any non-null argument
1 * subscriber.receive(_ as String) // any non-null argument that is-a String
1 * subscriber.receive({ it.size() > 3 }) // an argument that satisfies the given predicate
// (here: message length is greater than 3)
class MySpec extends Specification {
Subscriber subscriber = Mock {
1 * receive("hello")
1 * receive("goodbye")
}
}
with(mock) {
1 * receive("hello")
1 * receive("goodbye")
}
Stubs do not have cardinality (matches invokation anyTimes)
def subsriber = Stub(Subscriber)
...
subscriber.receive(_) >> "ok"
Whenever the subscriber receives a message, make it respond with ‘ok’
subscriber.receive(_) >>> ["ok", "error", "error", "ok"]
subscriber.receive(_) >>> ["ok", "fail", "ok"] >> { throw new InternalError() } >> "ok"
@Ignore(reason = "TODO")
@IgnoreRest
@IgnoreIf({ spock.util.environment.Jvm.isJava5()) })
@Requires({ os.windows })
@Timeout(5)
@Timeout(value = 100, unit = TimeUnit.MILLISECONDS)
@Title("This tests if..."
@Narrative("some detailed explanation")
@Issue("http://redmine/23432")
@Subject
The project can be cloned from github repository.
The revision described in this post is 550449af09030ced25653dfc0961b2cbfd05bbcb.
The syntax is simplified version of Java’s. You can specify type and name of a field. There are no are no modifiers and keywords like ‘static’,’volatile’,’transient’ etc. I am trying to keep it simple so far.
Fields {
int field
start {
field = 5
print field
}
}
Until now, you could only define methods in class body scope. It’s time to introduce fields:
classBody : field* function* ;
field : type name;
I also added assign statement for already defined variables:
assignment : name EQUALS expression;
To make use of fields you have to assign them to something. Turns out I have not yet implemented such a basic thing as assignment statement for already declared variables. Why haven’t I done that? Well It was kind of on purpose.
The reason behind it is I would like the variables to be constant (immutable). Assigning means changing state - changing state lead to many issues (synchronization,side effects,memory leaks).
Have you ever read a Java code and that looks something like this:
Stuff trustMeIWontModifyYourArg(SomeObject arg) {
... 999 lines of code
arg = null; //or some other nasty hidden stuff
...another 999 lines of code
}
By reading the signature you probably thought to yourself - “hmmm… does this method modify argument? Well, it does not have a final modifier but most of us (Java programmers) neglect it. Judging by it’s name it should not modify my args so let’s just use it.”
Two hours later you randomly get NullPointerException somewhere else in your code. The method modified your argument.
If you have no side effects in your methods you can easily make them parallel without worrying about synchronization issues and other nasty stuff. Such methods does not have a state = there are no side effects! The easiest way to achieve lack of side effects is to use values (constant variables) only.
You can learn more about statements and what’s wrong with them in awesome talk by Uncle Bob (the talk about assignments starts at 11:15): https://youtu.be/7Zlp9rKHGD4?t=11m15s. Check it out!
To declare a field you use asm’s library visitField method. It adds
the field to the fields[] member in the class structure and automatically
increases the fields_count counter:
public class FieldGenerator {
private final ClassWriter classWriter;
public FieldGenerator(ClassWriter classWriter) {
this.classWriter = classWriter;
}
public void generate(Field field) {
String name = field.getName();
String descriptor = field.getType().getDescriptor();
FieldVisitor fieldVisitor = classWriter.visitField(Opcodes.ACC_PUBLIC, name,descriptor, null, null);
fieldVisitor.visitEnd();
}
}
To get a field you need:
public class ReferenceExpressionGenerator {
//constructor and fields
public void generate(FieldReference fieldReference) {
String varName = fieldReference.geName();
Type type = fieldReference.getType();
String ownerInternalName = fieldReference.getOwnerInternalName();
String descriptor = type.getDescriptor();
methodVisitor.visitVarInsn(Opcodes.ALOAD,0);
methodVisitor.visitFieldInsn(Opcodes.GETFIELD, ownerInternalName,varName,descriptor);
}
}
ALOAD,0 - gets “this” object which is local variable at index 0. Non-static methods have “this” reference by default at index 0 in local variables.GETFIELD - opcode for reading field.public class AssignmentStatementGenerator {
//constructor and fields
public void generate(Assignment assignment) {
String varName = assignment.getVarName();
Expression expression = assignment.getExpression();
Type type = expression.getType();
if(scope.isLocalVariableExists(varName)) {
int index = scope.getLocalVariableIndex(varName);
methodVisitor.visitVarInsn(type.getStoreVariableOpcode(), index);
return;
}
Field field = scope.getField(varName);
String descriptor = field.getType().getDescriptor();
methodVisitor.visitVarInsn(Opcodes.ALOAD,0);
expression.accept(expressionGenerator);
methodVisitor.visitFieldInsn(Opcodes.PUTFIELD,field.getOwnerInternalName(),field.getName(),descriptor);
}
The local variables have priority over fields if there is ambiguity. If you declared local variable named exactly like a field you wouldn’t want to reference field but a variable, right? That is why the local variables are searched first.
The PUTFIELD opcode is similar to GETFIELD but pops additional item off the stack -
the result of expression to be assigned into field.
Following Enkel class:
Fields {
int field
start {
field = 5
print field
}
}
generates bytecode:
kuba@kuba-laptop:~/repos/Enkel-JVM-language$ javap -c Fields
public class Fields {
public int field;
public void start();
Code:
0: aload_0 //get "this"
1: ldc #9 // load constant "5" from constant pool
3: putfield #11 // Field field:I - pop 5 off the stack and write to field
6: getstatic #17 // Field java/lang/System.out:Ljava/io/PrintStream;
9: aload_0 //get "this" reference
10: getfield #11 // Field field:I
13: invokevirtual #22 // Method "Ljava/io/PrintStream;".println:(I)V
16: return
//autogenerated constructor and main method
}
The project can be cloned from github repository.
The revision described in this post is d0b8a3d711d9fd46f675d03ec4b506fbcb74ae22.
All JVM languages are compiled into bytecode, which is interpreted by the virtual machine. This means that compilers do not know what language the referencing classes are compiled from. As long as the class is on classpath it can be used, regardless of programming language.
This opens huge possibilities. All Java libraries,utilities and frameworks can now be used by Enkel.
When you reference class defined in different class file you have two choices:
In Enkel I decided to go with the second option - mainly due to safety reasons. It can be achieved using reflection api:
public class ClassPathScope {
public Optional<FunctionSignature> getMethodSignature(Type owner, String methodName, List<Type> arguments) {
try {
Class<?> methodOwnerClass = owner.getTypeClass();
Class<?>[] params = arguments.stream()
.map(Type::getTypeClass).toArray(Class<?>[]::new);
Method method = methodOwnerClass.getMethod(methodName,params);
return Optional.of(ReflectionObjectToSignatureMapper.fromMethod(method));
} catch (Exception e) {
return Optional.empty();
}
}
public Optional<FunctionSignature> getConstructorSignature(String className, List<Type> arguments) {
try {
Class<?> methodOwnerClass = Class.forName(className);
Class<?>[] params = arguments.stream()
.map(Type::getTypeClass).toArray(Class<?>[]::new);
Constructor<?> constructor = methodOwnerClass.getConstructor(params);
return Optional.of(ReflectionObjectToSignatureMapper.fromConstructor(constructor));
} catch (Exception e) {
return Optional.empty();
}
}
}
If the method (or constructor) is not found then the exception is thrown and the compilation process is terminated:
//Scope.java
return new ClassPathScope().getMethodSignature(owner.get(), methodName, argumentsTypes)
.orElseThrow(() -> new MethodSignatureNotFoundException(this,methodName,arguments));
This approach seems safer, but is also slower. All the dependencies must be resolved while compiling using expensive reflection.
Let’s try to call Library class from Client class:
Client {
start {
print "Client: Calling my own 'Library' class:"
var myLibrary = new Library()
var addition = myLibrary.add(5,2)
print "Client: Result returned from 'Library.add' = " + addition
}
}
Library {
int add(int x,int y) {
print "Library: add() method called"
return x+y
}
}
First we need to compile Library (no multiple files compilation is supported so far).
If we did not do this the Client compilation would fail due to unresolved reference
to Library class.
kuba@kuba-laptop:~/repos/Enkel-JVM-language$ java -classpath compiler/target/compiler-1.0-SNAPSHOT-jar-with-dependencies.jar:. com.kubadziworski.compiler.Compiler EnkelExamples/ClassPathCalls/Library.enk
kuba@kuba-laptop:~/repos/Enkel-JVM-language$ java -classpath compiler/target/compiler-1.0-SNAPSHOT-jar-with-dependencies.jar:. com.kubadziworski.compiler.Compiler EnkelExamples/ClassPathCalls/Client.enk
kuba@kuba-laptop:~/repos/Enkel-JVM-language$ java Client
Client: Calling my own 'Library' class:
Library: add() method called
Client: Result returned from 'Library.add' = 7
Client {
start {
var someString = "someString"
print someString + " to upper case : " + someString.toUpperCase()
}
}
kuba@kuba-laptop:~/repos/Enkel-JVM-language$ java Client
cos to upper case = COS
The project can be cloned from github repository.
The revision described in this post is c951b7b596889ba71070a33f4582a05beddab502.
What is the the greatest advantage of object oriented programming? In my opinion it is polymorphism. How do you achieve polymorphism? By using inheritance. Can you use inheritance with statics? No, of course not.
In my opinion statics violate the object oriented concepts, and should not be included in truly object oriented languages. Instead of using statics objects you are way better just by using singletons.
So why would Java call itself object oriented when there are statics? My theory is that for some historical reason they wanted C++ guys to adapt to Java quicker and “lure” as many as possible into java world.
Until last post (about object creation) all Enkel classes were purely static. They consisted of main method and other static methods. The reason behind this was to first implement all basic language features like variables,conditional statements,loops, method calls, and then move to OO. The time has come to start implementing OO.
All Java programs need to have static main method defined. The way Enkel handles this is as follows:
start method on the fresh new created object.start method.private Function getGeneratedMainMethod() {
FunctionParameter args = new FunctionParameter("args", BultInType.STRING_ARR, Optional.empty());
FunctionSignature functionSignature = new FunctionSignature("main", Collections.singletonList(args), BultInType.VOID);
ConstructorCall constructorCall = new ConstructorCall(scope.getClassName());
FunctionSignature startFunSignature = new FunctionSignature("start", Collections.emptyList(), BultInType.VOID);
FunctionCall startFunctionCall = new FunctionCall(startFunSignature, Collections.emptyList(), scope.getClassType());
Block block = new Block(new Scope(scope), Arrays.asList(constructorCall,startFunctionCall));
return new Function(functionSignature, block);
}
The start method is basically non-static version of main method.
In Creating JVM language [PART 7] - Methods
I used INVOKESTATIC for invoking methods. It’s time to change it to INVOKEVIRTUAL.
There is one important difference between both of them - INVOKEVIRTUAL requires owner.
INVOKESTATIC pops arguments off the stack. INVOKEVIRTUAL pops owner off the stack
and then it pops arguemnts. It’s mandatory to generate owner expression.
If there is no owner provided by a programmer the implicit “this” var reference is provided:
//Mapping antlr generated FunctionCallContext to FunctionCall
@Override
public Expression visitFunctionCall(@NotNull EnkelParser.FunctionCallContext ctx) {
//other stuff
boolean ownerIsExplicit = ctx.owner != null;
if(ownerIsExplicit) {
Expression owner = ctx.owner.accept(this);
return new FunctionCall(signature, arguments, owner);
}
ClassType thisType = new ClassType(scope.getClassName());
return new FunctionCall(signature, arguments, new VarReference("this",thisType)); //pass "this" as a owner
}
//Generating bytecode using mapped FunctionCall object
public void generate(FunctionCall functionCall) {
functionCall.getOwner().accept(this); //generate owner (pushses it onto stack)
generateArguments(functionCall); //generate arguments
String functionName = functionCall.getIdentifier();
String methodDescriptor = DescriptorFactory.getMethodDescriptor(functionCall.getSignature());
String ownerDescriptor = functionCall.getOwnerType().getInternalName();
//Consumes owner and arguments off the stack
methodVisitor.visitMethodInsn(Opcodes.INVOKEVIRTUAL, ownerDescriptor, functionName, methodDescriptor, false);
}
Following Enkel Class:
HelloStart {
start {
print "Hey I am non-static 'start' method"
}
}
get’s compiled into:
kuba@kuba-laptop:~/repos/Enkel-JVM-language$ javap -c HelloStart.class
public class HelloStart {
public void start();
Code:
0: getstatic #12 // Field java/lang/System.out:Ljava/io/PrintStream;
3: ldc #14 // String Hey I am non-static 'start' method
5: invokevirtual #19 // Method "Ljava/io/PrintStream;".println:(Ljava/lang/String;)V
8: return
//Constructor
public HelloStart();
Code:
0: aload_0 //get "this"
1: invokespecial #22 // Method java/lang/Object."<init>":()V - call super
4: return
public static void main(java.lang.String[]);
Code:
0: new #2 // class HelloStart - create new object
3: dup //duplicate new object so that invokespecial does not consumes it
4: invokespecial #25 // Method "<init>":()V - call constructor
7: invokevirtual #27 // Method start:()V
10: return
}
where Java’s equivalent would be:
public class HelloStart {
public HelloStart() {
}
public static void main(String[] var0) {
(new HelloStart()).start();
}
public void start() {
System.out.println("Hey I am non-static \'start\' method");
}
}
The project can be cloned from github repository.
The revision described in this post is c951b7b596889ba71070a33f4582a05beddab502.
Enkel’s constuctor declaration and invocation syntax are the same as Java’s (well except features like default and named parameters).
Declaration Example:
Cat ( String name ) {
}
Invocation:
new Cat ( "Molly" )
In Java the constructor declaration syntax is just a method declaration without return type. Turns out Enkel method declarations do not require specifing return value (if the method returns void). Therefore there is no need to specify new rule for constructor declaration.
But what about constructor call? How would a parser distinct between method call and constructor call? For that reason Enkel introduces ‘new’ keyword:
//other rules
expression : //other rules alternatives
| 'new' className '('argument? (',' argument)* ')' #constructorCall
The introduction of new rule alternative (constructorCall) leads to a new parse tree callback:
@Override
public Expression visitConstructorCall(@NotNull EnkelParser.ConstructorCallContext ctx) {
String className = ctx.className().getText();
List<EnkelParser.ArgumentContext> argumentsCtx = ctx.argument();
List<Expression> arguments = getArgumentsForCall(argumentsCtx, className);
return new ConstructorCall(className, arguments);
}
FunctionCall requires name,return type,arguments and owner expression provided for constructor. Constructor call however requires only className and arguments:
someObject.new SomeObject() would not make any sense.What about Constructor declaration? There is no rule alternative for it. How do we then distinguish between function declaration and constructor? Simply by checking if the name of the method is equal to the current Class name. It also means that regular methods cannot be named like a class:
@Override
public Function visitFunction(@NotNull EnkelParser.FunctionContext ctx) {
List<Type> parameterTypes = ctx.functionDeclaration().functionParameter().stream()
.map(p -> TypeResolver.getFromTypeName(p.type())).collect(toList());
FunctionSignature signature = scope.getMethodCallSignature(ctx.functionDeclaration().functionName().getText(),parameterTypes);
scope.addLocalVariable(new LocalVariable("this",scope.getClassType()));
addParametersAsLocalVariables(signature);
Statement block = getBlock(ctx);
//Check if method is not actually a constructor
if(signature.getName().equals(scope.getClassName())) {
return new Constructor(signature,block);
}
return new Function(signature, block);
}
Enkel also creates default constructor if you do not provide one:
@Override
public ClassDeclaration visitClassDeclaration(@NotNull EnkelParser.ClassDeclarationContext ctx) {
//some other stuff
boolean defaultConstructorExists = scope.parameterLessSignatureExists(className);
addDefaultConstructorSignatureToScope(name, defaultConstructorExists);
//other stuff
if(!defaultConstructorExists) {
methods.add(getDefaultConstructor());
}
}
private void addDefaultConstructorSignatureToScope(String name, boolean defaultConstructorExists) {
if(!defaultConstructorExists) {
FunctionSignature constructorSignature = new FunctionSignature(name, Collections.emptyList(), BultInType.VOID);
scope.addSignature(constructorSignature);
}
}
private Constructor getDefaultConstructor() {
FunctionSignature signature = scope.getMethodCallSignatureWithoutParameters(scope.getClassName());
Constructor constructor = new Constructor(signature, Block.empty(scope));
return constructor;
}
You may wonder why the constructor returns void. Roughlt speaking JVM divides object creation into two steps - first it allocates it, then it calls constructor (which responsibility is to initialize already created object). Thanks to that you can call “this” inside constructors.
We’ve got constructor declarations and invocations properly parsed and mapped to nice objects representing them. How to reach out data from them and generate bytecode?
Object creation in jvm bytecode is divided into two instruction:
NEW - allocates memory on the heap, initialize instance members to a default values (int - 0, boolean - false etc.)INVOKESPECIAL - calls constructorIn Java you do not need to call super() in the constructor, right? It is required - if you do not do this the java compiler does it automatically. The object cannot be created without calling super!
Invoking a super call happens using INVOKESPECIAL, and the Enkel compiler
handles it automatically (similarly to java compiler).
public void generate(ConstructorCall constructorCall) {
String ownerDescriptor = scope.getClassInternalName(); //example : java/lang/String
methodVisitor.visitTypeInsn(Opcodes.NEW, ownerDescriptor); //NEW instruction takes object decriptor as an input
methodVisitor.visitInsn(Opcodes.DUP); //Duplicate (we do not want invokespecial to "eat" our brand new object
FunctionSignature methodCallSignature = scope.getMethodCallSignature(constructorCall.getIdentifier(),constructorCall.getArguments());
String methodDescriptor = DescriptorFactory.getMethodDescriptor(methodCallSignature);
generateArguments(constructorCall);
methodVisitor.visitMethodInsn(Opcodes.INVOKESPECIAL, ownerDescriptor, "<init>", methodDescriptor, false);
}
You may wonder why do we need DUP instruction? After NEW instruction has been called the stack contains brand new created object. INVOKESPECIAL pops element (object) from the stack to initialize it. If we didn’t duplicate the object it would just be popped by constructor, and lost in the heap waited for GC to collect it.
The following statement:
new Cat().meow()
is then compiled into bytecode:
0: new #2 // class Cat
3: dup
4: invokespecial #23 // Method "<init>":()V
7: invokevirtual #26 // Method meow:()V
public void generate(Constructor constructor) {
Block block = (Block) constructor.getRootStatement();
Scope scope = block.getScope();
int access = Opcodes.ACC_PUBLIC;
String description = DescriptorFactory.getMethodDescriptor(constructor);
MethodVisitor mv = classWriter.visitMethod(access, "<init>", description, null, null);
mv.visitCode();
StatementGenerator statementScopeGenrator = new StatementGenerator(mv,scope);
new SuperCall().accept(statementScopeGenrator); //CALL SUPER IMPLICITILY BEFORE BODY ITSELF
block.accept(statementScopeGenrator); //CALL THE BODY DEFINED BY PROGRAMMER
appendReturnIfNotExists(constructor, block,statementScopeGenrator);
mv.visitMaxs(-1,-1);
mv.visitEnd();
}
As I mentioned above the super call is required to be the very first expression in every constructor. As a Java programmers we usually do not specify it (unless the superclass does not have parameterless constructor). It is not because it is not required - the java compiler generates it automatically. It would be awesome if Enkel compiler could do the same:
new SuperCall().accept(statementScopeGenrator);
invokes
public void generate(SuperCall superCall) {
methodVisitor.visitVarInsn(Opcodes.ALOAD,0); //LOAD "this" object
generateArguments(superCall);
String ownerDescriptor = scope.getSuperClassInternalName();
methodVisitor.visitMethodInsn(Opcodes.INVOKESPECIAL, ownerDescriptor, "<init>", "()V" , false);
}
Every method (even constructor) treats arguments as local variables in the frame.
If the method int add(int x,int y) was called in a static context
then its initial frame would consisted of 2 variables (x,y).
Additionally if the method is non-static it also puts this object (the object on which it was called)
in the frame (at position 0). So if the add method was called in a non-static context
it would have 3 local variables (this,x,y) out of the box.
The Cat constructor without any body specified by programmer would therefore look like:
0: aload_0 //load "this"
1: invokespecial #8 // Method java/lang/Object."<init>":()V - call super on "this" (the Cat dervies from Object)
12: return
The project can be cloned from github repository.
The revision described in this post is 30e678fea0847b84bb21154648104d343540908f.
So far Enkel supported integers and Strings only. It is time to include all the other primitive types. This step was also necessary to prepare a compiler for upcoming object oriented features coming soon (so far creating objects other than String is not possible).
There are many bytecode instructions that only differ from each other by type. Let’s take a look at the return instruction as an example:
It might be tempting to just add cases for each type in each section that emits bytecode instruction.
It would however result in awful ifology - we don’t want that.
Instead I decided to make an TypeSpecificOpcodes enum that stores all the opcodes for each type respectively and is reachable by Type enum:
public enum TypeSpecificOpcodes {
INT (ILOAD, ISTORE, IRETURN,IADD,ISUB,IMUL,IDIV), //values (-127,127) - one byte.
LONG (LLOAD, LSTORE, LRETURN,LADD,LSUB,LMUL,LDIV),
FLOAT (FLOAD, FSTORE, FRETURN,FADD,FSUB,FMUL,FDIV),
DOUBLE (DLOAD, DSTORE, DRETURN,DADD,DSUB,DMUL,DDIV),
VOID(ALOAD, ASTORE, RETURN,0,0,0,0),
OBJECT (ALOAD,ASTORE,ARETURN,0,0,0,0);
TypeSpecificOpcodes(int load, int store, int ret, int add, int sub, int mul, int div) {
//assign each parameter to the field
}
//getters
The (type aware) instructions used so far are:
The TypeSpecificOpcodes is composited in BultInType enum:
public enum BultInType implements Type {
BOOLEAN("bool",boolean.class,"Z", TypeSpecificOpcodes.INT),
//other members
BultInType(String name, Class<?> typeClass, String descriptor, TypeSpecificOpcodes opcodes) {
//assign to fields
}
@Override
public int getMultiplyOpcode() {
return opcodes.getMultiply();
}
No whenever multiply two values is taking place, there is no need to find opcode specific for expression type - it is already known by a Type. Just simply:
public void generate(Multiplication expression) {
evaluateArthimeticComponents(expression);
Type type = expression.getType();
methodVisitor.visitInsn(type.getMultiplyOpcode());
}
The following Enkel class:
main(string[] args) {
var stringVar = "str"
var booleanVar = true
var integerVar = 2745 + 33
var doubleVar = 2343.05
var sumOfDoubleVars = 23.0 + doubleVar
}
is compiled into following bytecode:
kuba@kuba-laptop:~/repos/Enkel-JVM-language$ javap -c AllPrimitiveTypes.class
public class AllPrimitiveTypes {
public static void main(java.lang.String[]);
Code:
0: ldc #8 // String str
2: astore_1 //store it variable
3: ldc #9 // int 1 - bool values are represented as ints in JVM
5: istore_2 //store as int
6: ldc #10 // int 2745
8: ldc #11 // int 33
10: iadd // iadd - add integers
11: istore_3 //store result in integer varaible
12: ldc #12 // float 2343.05f
14: fstore 4 //store in float variable
16: ldc #13 // float 23.0f
18: fload 4 //load integer varaible (from index 4)
20: fadd //add float variables
21: fstore 5 //store float result
23: return
}
As you can see the opcodes for the instructions are of the types corresponding to the expected types of a statements / expressions.