Creating JVM language [PART 13] - For Loops
Sources
The project can be cloned from github repository.
The revision described in this post is ebd36ca9f8af03ce4b9c144efab0ad11cc99f749.
Ranged loops
In this post I am going to describe ‘ranged for loops’. The ranged for loops iterate value within specified range. In Java range loop can look like this:
for (int i=0;i<=5;i++)
Enkel’s equivalent would be:
for i from 0 to 5
I also implemented additional feature. The loops are aware whether they should decrement or increment:
for i from 0 to 5 //increment i from 0 to 5 - for (int i=0;i<=5;i++)
for i from 5 to 0 //decremenet i from 5 to 0 - for (int i=5;i>=0;i--)
The loop type (incremented,decremented) must be inferred at runtime, because the ranges values can be results of method calls.
The concept for while loops and collections loops ( for ( item : collection) ) is very simmilar
. It is not described in this post to make it as short as possible.
Grammar changes
statement : block
//other statement alternatives
| forStatement ;
forStatement : 'for' ('(')? forConditions (')')? statement ;
forConditions : iterator=varReference 'from' startExpr=expression range='to' endExpr=expression ;
forConditionsare conditions (bounds) for the iterator (from i 0 to 10).- Labeling rules with
=is going to improve readability of the parser. - the iterator must be a name of the variable (the var may not exist in the scope. In this case the variable is declared behind the scenes)
- The startExpression’s value is used for initializing the iterator.
- The endExpressions’s value is the stop value for the iterator.
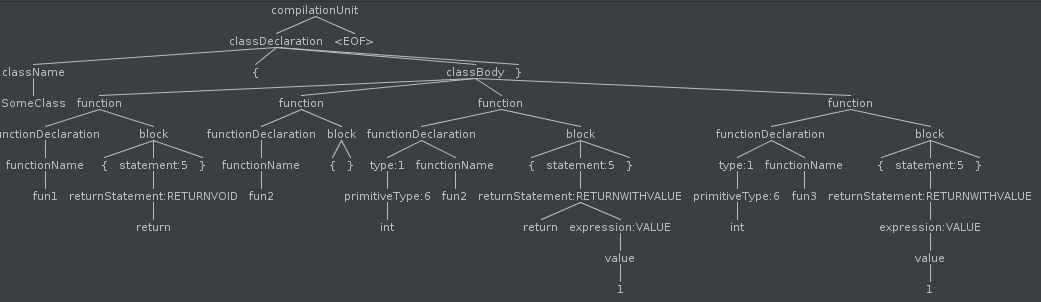
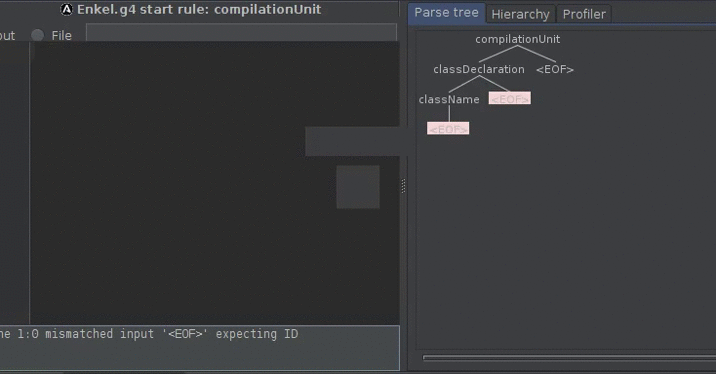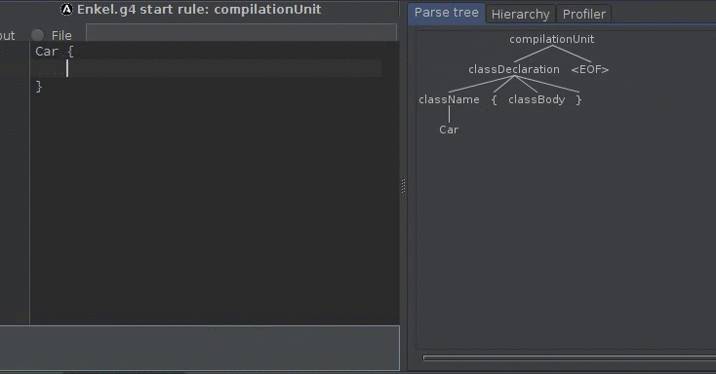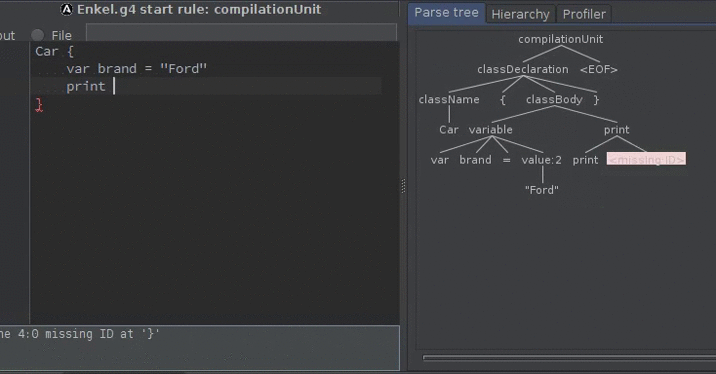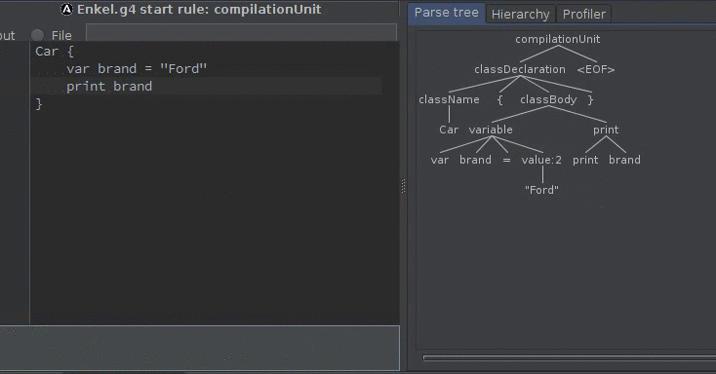
The result parse tree for the statement:
for (i from 0 to 5) print i
is:

Mapping antlr context objects
The antlr generates ForStatementContext class from the grammar specification. It is good idea to map it into more compiler-friendly class. While mapping why not solve the problem described in the previous section (undeclared iterator variable)?
public class ForStatementVisitor extends EnkelBaseVisitor<RangedForStatement> {
//other stuff
@Override
public RangedForStatement visitForStatement(@NotNull ForStatementContext ctx) {
EnkelParser.ForConditionsContext forExpressionContext = ctx.forConditions();
Expression startExpression = forExpressionContext.startExpr.accept(expressionVisitor);
Expression endExpression = forExpressionContext.endExpr.accept(expressionVisitor);
VarReferenceContext iterator = forExpressionContext.iterator;
String varName = iterator.getText();
//If variable referenced by iterator already exists in the scope
if(scope.localVariableExists(varName)) {
//register new variable value
Statement iteratorVariable = new AssignmentStatement(varName, startExpression);
//get the statement (usually block))
Statement statement = ctx.statement().accept(statementVisitor);
return new RangedForStatement(iteratorVariable, startExpression, endExpression,statement, varName, scope);
//Variable has not been declared in the scope
} else {
//create new local variable and add to the scope
scope.addLocalVariable(new LocalVariable(varName,startExpression.getType()));
//register variable declaration statement
Statement iteratorVariable = new VariableDeclarationStatement(varName,startExpression);
Statement statement = ctx.statement().accept(statementVisitor);
return new RangedForStatement(iteratorVariable, startExpression, endExpression,statement, varName,scope);
}
}
}
The iterator variable may or may not exist in the scope. Both statements below should be handled:
var iterator = 0
for (iterator from 0 to 5) print iterator
Iterator was already declared. Assign it to the the startExpression (value 0) : new AssignmentStatement(varName, startExpression);.
for (iterator from 0 to 5) print iterator
Iterator is not yet declared. Declare and assign it to the startExpression (value 0) : new VariableDeclarationStatement(varName,startExpression);.
Generating bytecode
Once the RangedForStatement has been created it is time to pull some information
from it and generate bytecode.
There are no special jvm instructions for loops. One way to do that is to use control flow (conditional and unconditional) instructions (described in Creating JVM language [PART 10] - Conditional statements).
public void generate(RangedForStatement rangedForStatement) {
Scope newScope = rangedForStatement.getScope();
StatementGenerator scopeGeneratorWithNewScope = new StatementGenerator(methodVisitor, newScope);
ExpressionGenrator exprGeneratorWithNewScope = new ExpressionGenrator(methodVisitor, newScope);
Statement iterator = rangedForStatement.getIteratorVariableStatement();
Label incrementationSection = new Label();
Label decrementationSection = new Label();
Label endLoopSection = new Label();
String iteratorVarName = rangedForStatement.getIteratorVarName();
Expression endExpression = rangedForStatement.getEndExpression();
Expression iteratorVariable = new VarReference(iteratorVarName, rangedForStatement.getType());
ConditionalExpression iteratorGreaterThanEndConditional = new ConditionalExpression(iteratorVariable, endExpression, CompareSign.GREATER);
ConditionalExpression iteratorLessThanEndConditional = new ConditionalExpression(iteratorVariable, endExpression, CompareSign.LESS);
//generates varaible declaration or variable reference (istore)
iterator.accept(scopeGeneratorWithNewScope);
//Section below checks whether the loop should be iterating or decrementing
//If the range start is smaller than range end (i from 0 to 5) then iterate (++)
//If the range start is greater than range end (i from 5 to 0) then decrement (--)
//Pushes 0 or 1 onto the stack
iteratorLessThanEndConditional.accept(exprGeneratorWithNewScope);
//IFNE - is value on the stack (result of conditional) different than 0 (success)?
methodVisitor.visitJumpInsn(Opcodes.IFNE,incrementationSection);
iteratorGreaterThanEndConditional.accept(exprGeneratorWithNewScope);
methodVisitor.visitJumpInsn(Opcodes.IFNE,decrementationSection);
//Incrementation section
methodVisitor.visitLabel(incrementationSection);
rangedForStatement.getStatement().accept(scopeGeneratorWithNewScope); //execute the body
methodVisitor.visitIincInsn(newScope.getLocalVariableIndex(iteratorVarName),1); //increment iterator
iteratorGreaterThanEndConditional.accept(exprGeneratorWithNewScope); //is iterator greater than range end?
methodVisitor.visitJumpInsn(Opcodes.IFEQ,incrementationSection); //if it is not go back loop again
//the iterator is greater than end range. Break out of the loop, skipping decrementation section
methodVisitor.visitJumpInsn(Opcodes.GOTO,endLoopSection);
//Decrementation section
methodVisitor.visitLabel(decrementationSection);
rangedForStatement.getStatement().accept(scopeGeneratorWithNewScope);
methodVisitor.visitIincInsn(newScope.getLocalVariableIndex(iteratorVarName),-1); //decrement iterator
iteratorLessThanEndConditional.accept(exprGeneratorWithNewScope);
methodVisitor.visitJumpInsn(Opcodes.IFEQ,decrementationSection);
methodVisitor.visitLabel(endLoopSection);
}
This may seem a little bit complicated because the decision whether the loop should be incremented or decremented needs to be taken at runtime.
Let’s analyze how the method actually choose the right iteration type in this example for (i from 0 to 5):
- Declare iterator varaible
iand assign start value (0). - Check if iterator value (
0) is less than end range value (5) - Because the
0(range start) is less than5(range end) the iterator should be incremented. Jump to incrementation section. - Execute the actual statements in the loop.
- increment iterator by
1 - Check if iterator is greater than range end (
5). - If it is not then go back to the point
4. - Once the loop has been executed 5 times (the iterator is 6) go to end section (skip decrementation section)
Example
Let’s compile the following Enkel class:
Loops {
main(string[] args) {
for i from 1 to 5 {
print i
}
}
}
To better present how the iteration type is inferred I decompiled the Enkel.class file using Intellij Idea’s decompiler:
//Enkel.class file decompiled to Java using Intellij Idea's decompiler
public class Loops {
public static void main(String[] var0) {
int var1 = 1;
if(var1 >= 5 ) { //should it be decremented?
do {
System.out.println(var1);
--var1;
} while(var1 >= 5);
} else { //should it be incremented?
do {
System.out.println(var1);
++var1;
} while(var1 <= 5);
}
}
}
The result is obviously :
kuba@kuba-laptop:~/repos/Enkel-JVM-language$ java Loops
1
2
3
4
5